统计模式识别(卷名:自动控制与系统工程)
statistical approach of pattern recognition
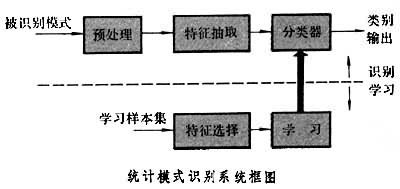 对模式的统计分类方法,即把模式类看成是用某个随机向量实现的集合,又称为决策理论识别方法(见模式识别)。属于同一类别的各个模式之间的差异,部分是由环境噪声和传感器的性质所引起的,部分是模式本身所具有的随机性质。前者如纸的质量、墨水、污点对书写字符的影响;后者表现为同一个人书写同一字符时,虽形状相似,但不可能完全一样。因此当用特征向量来表示这些在形状上稍有差异的字符时,同这些特征向量 对应的特征空间中的点便不同一,而是分布在特征空间的某个区域中。这个区域就可以用来表示该随机向量实现的集合。假使在特征空间中规定某种距离度量,从直观上看,两点之间的距离越小,它们所对应的模式就越相似。在理想的情况下,不同类的两个模式之间的距离要大于同一类的两个模式之间的距离,同一类的两点间连接线上各点所对应的模式应属于同一类。一个畸变不大的模式所对应的点应紧邻没有畸变时该模式所对应的点。在这些条件下,可以准确地把特征空间划分为同各个类别相对应的区域。在不满足上述条件时,可以对每个特征向量估计其属于某一类的概率,而把有最大概率值的那一类作为该点所属的类别。统计模式识别方法就是用给定的有限数量样本集,在已知研究对象统计模型或已知判别函数类条件下根据一定的准则通过学习算法把d 维特征空间划分为c个区域,每一个区域与每一类别相对应。模式识别系统在进行工作时只要判断被识别的对象落入哪一个区域,就能确定出它所属的类别。由噪声和传感器所引起的变异性,可通过预处理而部分消除;而模式本身固有的变异性则可通过特征抽取和特征选择得到控制,尽可能地使模式在该特征空间中的分布满足上述理想条件。因此一个统计模式识别系统应包含预处理、特征抽取、分类器等部分(见图)。
对模式的统计分类方法,即把模式类看成是用某个随机向量实现的集合,又称为决策理论识别方法(见模式识别)。属于同一类别的各个模式之间的差异,部分是由环境噪声和传感器的性质所引起的,部分是模式本身所具有的随机性质。前者如纸的质量、墨水、污点对书写字符的影响;后者表现为同一个人书写同一字符时,虽形状相似,但不可能完全一样。因此当用特征向量来表示这些在形状上稍有差异的字符时,同这些特征向量 对应的特征空间中的点便不同一,而是分布在特征空间的某个区域中。这个区域就可以用来表示该随机向量实现的集合。假使在特征空间中规定某种距离度量,从直观上看,两点之间的距离越小,它们所对应的模式就越相似。在理想的情况下,不同类的两个模式之间的距离要大于同一类的两个模式之间的距离,同一类的两点间连接线上各点所对应的模式应属于同一类。一个畸变不大的模式所对应的点应紧邻没有畸变时该模式所对应的点。在这些条件下,可以准确地把特征空间划分为同各个类别相对应的区域。在不满足上述条件时,可以对每个特征向量估计其属于某一类的概率,而把有最大概率值的那一类作为该点所属的类别。统计模式识别方法就是用给定的有限数量样本集,在已知研究对象统计模型或已知判别函数类条件下根据一定的准则通过学习算法把d 维特征空间划分为c个区域,每一个区域与每一类别相对应。模式识别系统在进行工作时只要判断被识别的对象落入哪一个区域,就能确定出它所属的类别。由噪声和传感器所引起的变异性,可通过预处理而部分消除;而模式本身固有的变异性则可通过特征抽取和特征选择得到控制,尽可能地使模式在该特征空间中的分布满足上述理想条件。因此一个统计模式识别系统应包含预处理、特征抽取、分类器等部分(见图)。分类器有多种设计方法,如贝叶斯分类器、树分类器、线性判别函数、近邻法分类、最小距离分类、聚类分析等。
参考书目
C.H.Chen, Statistical Pattern Recognition,Hayden(Sparton Books), New York,1973.
K.Fukunaga,Introduction to Statistical Pattern Recognition,Academic Press, New York,1972.
S.Watanabe,ed.,Methodologies of Pattern Recognition,Academic Press, New York, 1969.