信息率-失真理论(卷名:电子学与计算机)
information rate-distortion theory
研究在限定失真下为了恢复信源符号所必需的信息率,简称率失真理论。信源发出的符号传到信宿后,一般不能完全保持原样,而会产生失真。要避免这种失真几乎是不可能,而且也无必要,因为信宿不管是人还是机器,灵敏度总是有限的,不可能觉察无穷微小的失真。倘若在处理信源符号时允许一定限度的失真,可减小所必需的信息率,有利于传输和存储。率失真理论就是用以计算不同类型的信源在各种失真限度下所需的最小信息率。因此,这一理论是现代所有信息处理问题的理论基础。
在50年代,信息论主要研究无失真的信息传输问题。信源编码着眼于无失真地恢复信源符号的最小信息率。1959年,C.E.仙农发表《逼真度准则下的离散信源编码定理》一文,提出了率失真函数的概念,逐渐形成率失真理论并不断得到完善。这一理论能解决许多类型的信源问题,并扩大到多用户相关信源问题。
率失真函数 计算率失真函数是率失真理论的中心问题。要定义率失真函数,必须先定量地表达失真的程度,因此需要规定失真函数d(u,v)。u是信源符号U的样,u∈A,A是信源集,可以是连续的实数区间,也可以是离散的有限集如A={ɑ1,ɑ2,…,ɑn}。v 是信宿得到的符号V 的样,v∈B,B可以等于A也可以不同。因此失真函数d 是一个二元函数。当用v代替u不引起失真时,可使d(u,v)=0,若引起失真,就按失真程度规定d(u,v)为正实数集内的一个数。由于U 和V 都是随机量,d(u,v)也将是随机量,因此还须定义平均失真
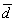 作为失真的度量,即
作为失真的度量,即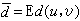 式中E表示取数学期望。
式中E表示取数学期望。当信源和信宿是随机序列U1,U2,…,UN和V1,V2,…,VN时,可定义平均失真为
 式中ur和vr分别为第r个信源和信宿符号ur、vr的样,各失真函数dr可以是同一函数,也可以是不同的函数。对于连续参量t的随机过程的信源和信宿,可把上面的求和改成积分,即
式中ur和vr分别为第r个信源和信宿符号ur、vr的样,各失真函数dr可以是同一函数,也可以是不同的函数。对于连续参量t的随机过程的信源和信宿,可把上面的求和改成积分,即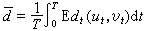
有了平均失真就可定义率失真函数。若信源和信宿都是离散的,P(u)和Q(v)分别为它们的概率,则
 式中P(v│u)是U 和V间的条件概率。则U和V间的互信息为
式中P(v│u)是U 和V间的条件概率。则U和V间的互信息为 而率失真函数为
而率失真函数为 式中PD为所有满足平均失真不大于D的条件概率P(v|u)的集,即
式中PD为所有满足平均失真不大于D的条件概率P(v|u)的集,即
当信源概率P(u)已给定时,I(U;V)是各P(v│u)的函数。在PD中选一组P(v│u)使I(U;V)最小,这最小值将是D的函数,这就是率失真函数R(D),也就是使恢复信源符号时平均失真不大于D所需的最小信息率。这一定义对于连续信源仍然适用,只要将P(u)和P(v│u)理解为概率密度,表达式中的求和号改为积分即可。
当信源概率P(u)已知,失真函数d(u,v)已规定时,可用求极值法来计算R(D)函数。实际计算一般相当复杂,有时尚须借助于计算机作迭代运算。最常见的二元信宿在对称失真函数时,率失真函数(图1)是
 式中p为较少出现的信源符号的概率,即
式中p为较少出现的信源符号的概率,即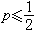 ,失真函数是
,失真函数是d(0,0)=d(1,1)=0 d(0,1)=d(1,0)=ɑH 是熵函数,即
H(z)=-zlogz-(1-z)log(1-z) (0≤z≤1)
正态信源在均方失真的规定下,率失真函数是
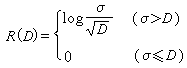 式中σ2为正态信源的方差。失真函数d(u,v)=(u-v)2(图2)。
式中σ2为正态信源的方差。失真函数d(u,v)=(u-v)2(图2)。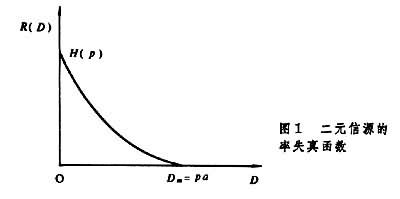

其实,其他信源的率失真函数也都与上述两种情况有类似的趋势,即对于离散信源,R(0)=H(p),对于连续信源,R(0)→∞;两者都有一个最大失真值Dm,当D≥Dm时,R(D)=0。此外,R(D)必为D的严格递减下凸函数,这些都可由定义直接推出。
限失真信源编码定理 率失真函数只指出限失真条件下所必需的最小信息率。从理论上讲,尚应能证明实际存在一种编码方法,用这样的信息率就能实现限失真的要求。这就是限失真信源编码定理。这个定理可表述为:只要信源符号序列长度N足够大,当每个符号的信息率大于R(D),必存在一种编码方法,其平均失真可无限逼近D;反之,若信息率小于R(D),则任何编码的平均失真必将大于D。
对于无记忆平稳离散信源,上述定理已被严格证明,并知其逼近误差是依指数关系 e
 而衰减的。其中B(R)是信息率R的函数,当R>R(D)时,B(R)是正值,且随R的增大而增大。因此当序列长度N增大时,误差将趋于零。对于其他信源,结果还不十分完善。
而衰减的。其中B(R)是信息率R的函数,当R>R(D)时,B(R)是正值,且随R的增大而增大。因此当序列长度N增大时,误差将趋于零。对于其他信源,结果还不十分完善。参考书目
T.Berger, Rate Distortion Theory,Prentice Hall, Engle wood Cliffs,New Jersey,1971.