实验设计(卷名:心理学)
experimental design
研究者在实验前根据研究目的拟定的实验计划及方法策略。其主要内容是合理安排实验程序,并提出将如何对实验数据作统计分析、心理实验设计的主要步骤可归纳为:①根据研究目的提出假设;②拟定验证假设的方法、程序;③选择适当的处理、分析实验数据的统计方法。
功能及其评价 实验设计的主要功能是对变量的控制,首先是在控制条件下有效地操纵或改变自变量,使因变量(即反应变量)的变化得到观察。例如,研究两种教学方法对儿童学业成就的影响时,实验设计者应安排使其他条件尽量相同,如选择家庭和学校环境相似、学业基础相似,年龄相同的两组儿童,只控制使用两种不同的教学方法,然后考查二者对学习结果的影响。良好的实验设计主要表现在合理安排实验程序,对无关变量进行有效的控制。心理学实验中的无关变量,有些可以象理化实验那样通过一定的实验仪器及技术予以排除,但大部分难以排除,因而必须依靠实验设计平衡或抵消其影响。这种控制方法称作实验控制法,常用的有几种:①消除或保持恒定法:主要利用实验室条件排除无关变量的干扰,对于不能排除的年龄、体重、实验环境、被试水平等变量,则设法使其保持恒定;②平衡法:即按随机原则将被试分为实验组与控制组,使无关变量对两组的影响均等;③抵消法:其目的在于控制由于实验顺序造成的影响,主要采用循环方式(只有两个实验处理时采用AB、BA法);④纳入法:即把某种无关变量当作自变量处理,使实验从单因素变为多因素设计,然后对结果进行多元统计分析,从中找出每个自变量的单独作用及交互作用。还有一些无关变量,虽然明知它对结果有影响,但限于实验条件,不可能用实验控制法加以平衡或抵消,而只能在实验结束后,用统计的方法分析出来,从结论中排除。这种控制方法叫做统计控制法。常用的统计控制法主要是协方差分析或称共变量分析。当研究工作由于事实上的困难或行政上的理由不能以个人为单位进行随机抽样、必须保持其团体的完整性(如以班级为单位)时,常使用这种方法。
评价一个实验设计可以有许多标准,但主要是看其能否充分发挥以下功能:①恰当地解决研究者所要解决的问题,即实验设计必须与研究问题匹配;②有较好的“内在效度”,即能够有效地控制无关变量,使反应变量的变化完全由自变量决定;③实验结果应具有一定的科学性、普遍性,能够推论到其他被试或其他情境,即有较高的“外在效度”。
基本类型 常用的心理实验设计有几种基本类型,而这些类型常常是被综合使用的。
单组设计与对比设计 根据是否设置控制组(对照组)划分的两种基本设计类型。
①单组设计。在所选被试编组时不设置控制组,其基本模式是前测-处理-后测,通过前后两次测量的差异检验实验处理的效果。统计结果一般采用t检验法。目前单独使用这种类型的实验设计已不多见。因为在前测与后测中间有许多因素,如成熟、前测对后测的影响、测量工具的变形、情境的改变等,与实验处理的效果相混淆,从而降低实验的内在效度。
②对比设计。这是心理实验最基本的设计之一。它把被试分为两组,一组为实验组,施以实验处理(也称处理);另一组为控制组,不加实验处理。为使两组被试尽量同质,便于比较,一般采用随机分派法分组,通过测量两组的差异检验实验处理的效果。其基本模式如Ⅰ。
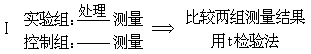 即使随机分派被试,但样本不很大时也很难保证两组在处理前同质,因而两组测量的差异不一定全是处理的结果。为了弥补这一不足,常在处理前先对两组进行测量,即模式Ⅱ。
即使随机分派被试,但样本不很大时也很难保证两组在处理前同质,因而两组测量的差异不一定全是处理的结果。为了弥补这一不足,常在处理前先对两组进行测量,即模式Ⅱ。 如果前测的结果相近,可直接比较两组的后测,并用t检验法检验其差异,这时的差异即可认为完全是由处理造成的。如果两个前测不同,就要把前测作为共变量,进行独立样本单因素的共变量分析。这种设计的优点是克服了大部分影响内在效度的无关变量。但由于有前测,又增加了前测的反作用效果,使外在效果有所降低。所谓测验的反作用效果是指处理前进行的前测可能增加或减少被试对处理的敏感性。
如果前测的结果相近,可直接比较两组的后测,并用t检验法检验其差异,这时的差异即可认为完全是由处理造成的。如果两个前测不同,就要把前测作为共变量,进行独立样本单因素的共变量分析。这种设计的优点是克服了大部分影响内在效度的无关变量。但由于有前测,又增加了前测的反作用效果,使外在效果有所降低。所谓测验的反作用效果是指处理前进行的前测可能增加或减少被试对处理的敏感性。完全随机化设计与随机区组设计 根据分组与处理方式划分的两种基本设计类型。
①完全随机化设计。又称被试间设计或独立组设计。它起源于抽样理论,即依据概率统计的原则,把被试随机分派到各组,接受各组应进行的处理。由于是随机分派,所以在理论上各组接受处理前各方面是相等的。如果在同样条件下对两个或两个以上组施以相同处理,则各组效果的平均数在统计上应没有显著差异;如果对两个或两个以上组分别施以不同的处理,所得效果平均数的差异可被断定是由于处理的不同而造成的。这种设计的实验结果一般采用独立样本的t检验或方差分析。在对比设计中所列的模式Ⅲ和Ⅳ,都可以说是完全随机化设计,也可以算作对比设计。
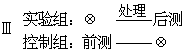 模式Ⅲ的特点是实验组不进行前测,控制组不进行后测。由于被试是随机分派的,实验组与控制组被看作同质,所以比较控制组的前测与实验组的后测,即可推断处理的效果。这种交叉前后测法虽在理论上能克服前测的不良影响,但较为理想的随机对比设计则是模式Ⅳ。它是把被试随机分为4组,即两个实验组和两个控制组,每两个之中都是一个有前测另一个无前测。模式表中的Y1、Y2、Y3、Y4均为后测的结果。用独立样本2×2方差分析法检验“前测与无前测的差异”、“实验处理与无处理的差异”以及“前测与处理交互作用是否显著”,就能既克服前测存在的反作用,又防止实验组与控制组可能出现不同质的状况。这种设计虽然比较理想,但它的被试有4组,人数多、实验次数也多,因而不够经济。
模式Ⅲ的特点是实验组不进行前测,控制组不进行后测。由于被试是随机分派的,实验组与控制组被看作同质,所以比较控制组的前测与实验组的后测,即可推断处理的效果。这种交叉前后测法虽在理论上能克服前测的不良影响,但较为理想的随机对比设计则是模式Ⅳ。它是把被试随机分为4组,即两个实验组和两个控制组,每两个之中都是一个有前测另一个无前测。模式表中的Y1、Y2、Y3、Y4均为后测的结果。用独立样本2×2方差分析法检验“前测与无前测的差异”、“实验处理与无处理的差异”以及“前测与处理交互作用是否显著”,就能既克服前测存在的反作用,又防止实验组与控制组可能出现不同质的状况。这种设计虽然比较理想,但它的被试有4组,人数多、实验次数也多,因而不够经济。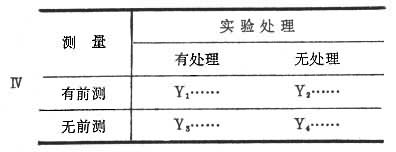
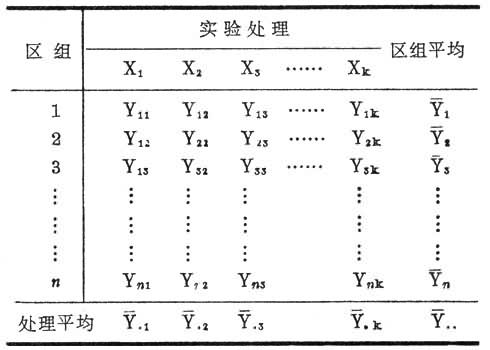
②随机区组设计。又称被试内设计。它先把被试按某些特质分到不同区组,使各区组内的被试更接近同质,而区组间的被试更加不同。然后将各区组内的被试随机分派接受不同的处理,或按不同顺序接受所有的处理。这样,对于一个区组来说是接受所有处理的。这一点与完全随机化设计不同。完全随机化设计中各组只分别接受各自所应该接受的处理。Ⅴ是随机区组设计的基本模式。它与完全随机化设计的不同还表现在把“区组”这一变量也纳入了实验设计。这样,总变异就可以分成“处理间”、“区组间”及“误差”。与完全随机化设计相比,它能把由个别差异造成的变异估计出来。划分区组的依据与要考察的反应变量密切相关,即当同一区组的被试在第1个实验处理中得分高于其他区组时,在第2个处理中的得分也同样高。因此,随机区组设计的统计方法一般用相关样本的t检验或方差分析。另外,如果随机区组设计中的每一区组都进行所有的处理,便称为完全区组设计;如果每区组所进行的处理数小于总的处理数,则称为不完全区组设计。后者虽然每一区组不进行所有的处理,但每一处理所在的区组数须相同。大部分心理学家在实验中的处理数都不太多,基本上是用完全区组设计。若处理数很多(农业实验中常遇到这种情况),由于实验的总实施次数很大,限于人力、财力及时间,则须采用不完全区组设计。
单因素设计与多因素设计 这两种设计是根据实验中自变量的多少来划分的。
①单因素设计。它的自变量只有一个,其他能影响结果的因素均作为无关变量而加以控制。这种设计简明易行,但由于在实际生活中影响心理活动的因素常不止一个,所以当情况比较复杂时,最好使用多因素实验设计。
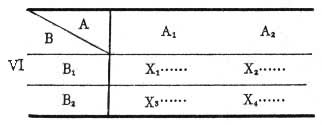
②多因素设计。自变量为两个或两个以上的实验设计。常用的多因素设计有完全随机化、随机区组和拉丁方等。完全随机化多因素设计根据自变量及每个自变量的变化水平(处理)的多少进行随机分组。在2×2因素设计中,有两个自变量因素A、B,每个因素又有两种水平,共有 4种可能的处理,即A1B1、A1B2、A2B1、A2B2。这就必须随机地把被试分为4组,每组接受一种处理,即模式Ⅵ。通过独立样本的2×2因素方差分析,可以分析出因素A或B的单独作用及A与B的交互作用。随机区组多因素设计则需在2×2因素设计中选一组被试,让每一个被试都接受4种处理,在次序上哪个人先接受哪种处理用随机法决定,这样,每一个人的4种处理结果就是一个区组。该设计所采用的统计方法用相关样本的方差分析。
拉丁方实验设计能以较少的实验次数完成实验目的。例如,A、B、C3种因素各有3个水平,需做33=27次实验。若采用拉丁方设计就不必做那么多次。在这种设计中,A、B两个因素的安排如Ⅶ。

根据这样的安排,共9次实验。同时还要考虑C,要使它的每一水平与其他两个因素的不同水平各组合1次,总实验次数仍为9次如Ⅷ。
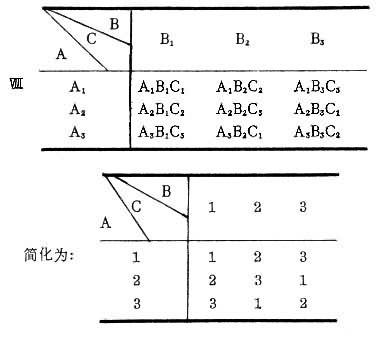
由于此设计常用拉丁字母,故称这种排列方式为拉丁方。其统计方法是拉丁方变异数分析。这种设计除了可减少总实验次数外,还有一个最大的优点,即能平衡实验顺序的影响。但利用它时必须符合一定的条件,即假设各因素之间没有交互作用,且因素的个数必须与实验处理水平数相同。
准实验设计 当研究者事先已认识到某些无关变量会影响实验结果但实际上却又难以妥善控制时,可采用准实验设计。准实验的主要特点是没有采用随机化程序,即被试的选择和编组、处理分配等都不是随机安排的。
准实验设计的主要类型有:①间歇时间序列设计:指在实施处理前后的一段时间里对一个被试组进行多次重复观测,通过比较整个时间序列的观测结果来确定处理的效果。所得结果的分析,需要对处理前后的一系列观测值作出检验和比较,通常采用相关样本t检验法。②相等时间样本设计:指在两段相等的时间里测量一个被试组,其中的一段时间给予处理,另一段时间不给予处理,然后对在两段相等时间里得到的观测值进行检验和比较。③非同质控制组前测后测设计:其基本模式如下:
 从表面上看,该模式与对比设计中的模式Ⅱ相同,但由于没有采用随机化程序,实验组和控制组是非同质的,对结果的统计处理所常用的方法是基础方差分析和协方差分析等。④平衡对抗设计:指在实验处理的顺序上提供控制,以抵消处理先后顺序的影响所产生的顺序误差。在单组仅有后测的实验中,如果有两种处理A和B,采用平衡对抗设计就是按ABBA的顺序进行处理。
从表面上看,该模式与对比设计中的模式Ⅱ相同,但由于没有采用随机化程序,实验组和控制组是非同质的,对结果的统计处理所常用的方法是基础方差分析和协方差分析等。④平衡对抗设计:指在实验处理的顺序上提供控制,以抵消处理先后顺序的影响所产生的顺序误差。在单组仅有后测的实验中,如果有两种处理A和B,采用平衡对抗设计就是按ABBA的顺序进行处理。非实验设计 通常是一种自然描述,用来确定自然存在的临界变量及其相互关系。非实验研究的方法很多,如自然观察法、相关法、访谈法、问卷法、测验法、个案法和传记法等。在非实验研究中,研究者既不采用随机化程序,也不能主动操纵自变量和控制其他无关变量。
非实验设计主要有以下几种主要类型:①单组后测设计:对一个被试组给予一次处理和一次后测。②单组前测后测设计:对一个被试组进行前测、处理和后测。这两个研究设计都没有控制组。③静态组比较设计:对在处理前已经组织起来的两个原组(非随机选择的)中的一个原组给予处理和后测,而对另一原组不给予处理仅作后测,然后比较两组的结果。④事后回溯设计:在一事件发生之后才着手收集有关此一事件的各种资料,分析此一事件的效果和原由。由于非实验设计是真实验设计的组成部分或重要元素,所以也称为前实验设计。
参考书目
赫葆源、张厚粲、陈舒永等编:《实验心理学》,北京大学出版社,北京,1982。
黄希庭主编:《心理学实验指导》,人民教育出版社,北京,1988。
D.T.Campbell and J.C.Stanley,Experimental and Quasi-experimental Designs for Research, Rand-McNally,Chicago,1966.
R. Plutchik, Foundations of Experimental Research,2nd ed.,Harper and Row,New York,1974.