模糊聚类分析(卷名:自动控制与系统工程)
fuzzy clustering analysis
涉及事物之间的模糊界限时按一定要求对事物进行分类的数学方法。聚类分析是数理统计中的一种多元分析方法,它是用数学方法定量地确定样本的亲疏关系,从而客观地划分类型。事物之间的界限,有些是确切的,有些则是模糊的。例如人群中的面貌相像程度之间的界限是模糊的,天气阴、晴之间的界限也是模糊的。当聚类涉及事物之间的模糊界限时,需运用模糊聚类分析方法。模糊聚类分析广泛应用在气象预报、地质、农业、林业等方面。通常把被聚类的事物称为样本,将被聚类的一组事物称为样本集。模糊聚类分析有两种基本方法:系统聚类法和逐步聚类法。
系统聚类法 系统聚类法是基于模糊等价关系的模糊聚类分析法。在经典的聚类分析方法中可用经典等价关系对样本集X进行聚类。设R是 X上的经典等价关系。对X中的两个元素x和y,若xRy或(x,y)∈R,则将x和y并为一类,否则x和y不属于同一类。
相应地,可用X上的模糊等价关系对样本集X进行模糊聚类。设慒是X上的模糊等价关系,
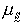 是慒 的隶属函数。对于任何α∈[0,1],定义慒 的α截关系
是慒 的隶属函数。对于任何α∈[0,1],定义慒 的α截关系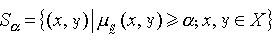 Sα是X上的经典等价关系。根据Sα得到X 的一种聚类,称为在α水平上的聚类。即对于X中的任意两个元素x和y,若
Sα是X上的经典等价关系。根据Sα得到X 的一种聚类,称为在α水平上的聚类。即对于X中的任意两个元素x和y,若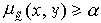 ,则x和y属于同一类;否则x和y不属于同一类。
,则x和y属于同一类;否则x和y不属于同一类。应用这种方法,分类的结果与α的取值大小有关。α取值越大,分的类数越多。α小到某一值时,X中的所有样本归并为一类。这种方法的优点在于可按实际需要选取α的值,以便得到恰当的分类。
系统聚类法的步骤如下:
①用数字描述样本的特征。设被聚类的样本集为 X={x1,…,xn}。每个样本均有p种特征,记作xi=(xi1,…,xip);i=1,2,…,n;xip表示描述样本xi的第p个特征的数。 ②规定样本之间的相似系数rij(0≤rij≤1;i,j=1,…,n)。rij描述样本xi与xj之间的差异或相似的程度。rij 越接近于1,表明样本xi与xj之间的差异越小;rij 越接近于0,表明xi与xj之间的差异越大。rij可用主观评定或集体评分的方法规定,也可用公式计算,如采用夹角余弦法、最小最大法、算术平均最小法等。
因为rii=1(xi与自身没有差异),rij=rji(xi与xj之间的差异等同于xj与xi之间的差异),所以由rij(i,j=1,…,n)可得X上的模糊相似关系:
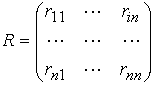 一般,R不具备可传递性,因而R不一定是 X上的模糊等价关系。
一般,R不具备可传递性,因而R不一定是 X上的模糊等价关系。③运用合成运算R2=R⋅R(或R4=R2⋅R2等)求出最接近相似关系R的模糊等价关系S=R2(或R4等)。若R已是模糊等价关系,则取S=R。
④选取适当水平α(0≤α≤1),得到X 的一种聚类。
逐步聚类法 逐步聚类法是一种基于模糊划分的模糊聚类分析法。它是预先确定好待分类的样本应分成几类,然后按最优化原则进行再分类,经多次迭代直到分类比较合理为止。
在分类过程中可认为某个样本以某一隶属度隶属于某一类,又以另一隶属度隶属于另一类。这样,样本就不是明确地属于或不属于某一类。若样本集有 n个样本要分成c类,则它的模糊划分矩阵为
 此c×n模糊划分矩阵有下列特性:①uij∈[0,1];i=1,…,c;j=1,…,n。②
此c×n模糊划分矩阵有下列特性:①uij∈[0,1];i=1,…,c;j=1,…,n。②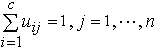 即每一样本属于各类的隶属度之和为1。③
即每一样本属于各类的隶属度之和为1。③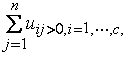 即每一类模糊子集都不是空集。
即每一类模糊子集都不是空集。模糊划分矩阵有无穷多个,这种模糊划分矩阵的全体称为模糊划分空间。最优分类的标准是样本与聚类中心的距离平方和最小。因为一个样本是按不同的隶属度属于各类的,所以应同时考虑它与每一类的聚类中心的距离。逐步聚类法需要反复迭代计算,计算工作量很大,要在电子计算机上进行。算出最优模糊划分矩阵后,还必须求得相应的常规划分。此时可将得到的聚类中心存在计算机中,将样本重新逐个输入,去与每个聚类中心进行比较,与哪个聚类中心最接近就属于哪一类。
这种方法要预先知道分类数,如分类数不合理,就重新计算。这就不如运用基于模糊等价关系的系统聚类法,但可以得到聚类中心,即各类模式样本,而这往往正是所要求的。因此可用模糊等价关系所得结果作为初始分类,再通过反复迭代法求得更好的结果。