列联表(卷名:数学)
contingency table
观测数据按两个或更多属性(定性变量)分类时所列出的频数表。例如,对随机抽取的1000人按性别(男或女)及色觉(正常或色盲)两个属性分类,得到二行二列的列联表(表1
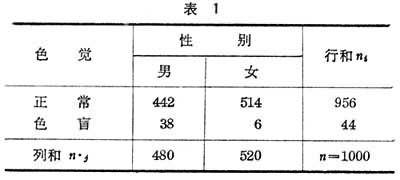 ),又称2×2表或四格表。
),又称2×2表或四格表。一般,若总体中的个体可按两个属性A与B分类,A有r个等级A1,A2,…,Ar;B有с个等级B1,B2,…,Bc,从总体中抽取大小为n的样本设其中有nij个属于等级Ai和Bj,nij称为频数,将r×с个nij(i=1,2,…,r;j=1,2,…,с)排列为一个r行с列的二维列联表(表2
 ),简称r×с表。若所考虑的属性多于两个,也可按类似的方式作出列联表,称为多维列联表。由于属性或定性变量的取值是离散的,因此多维列联表分析属于离散多元分析的范畴,列联表分析在应用统计,特别在医学、生物学及社会科学中,有重要的应用。
),简称r×с表。若所考虑的属性多于两个,也可按类似的方式作出列联表,称为多维列联表。由于属性或定性变量的取值是离散的,因此多维列联表分析属于离散多元分析的范畴,列联表分析在应用统计,特别在医学、生物学及社会科学中,有重要的应用。列联表分析的基本问题是,判明所考察的各属性之间有无关联,即是否独立。如在前例中,问题是:一个人是否色盲与其性别是否有关?在 r×с表中,若以pi·、p·j 和pij分别表示总体中的个体属于等级Ai,属于等级Bj和同时属于Ai、Bj的概率(pi·, p·j称边缘概率,pij称格概率),“A、B两属性无关联”的假设可以表述为H0:pij=pi·p·j,(i=1,2,…,r;j=1,2,…,с),未知参数 pij、pi·、p·j的最大似然估计(见点估计)分别为
 分别为行和及列和(统称边缘和);
分别为行和及列和(统称边缘和);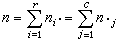 为样本大小。根据K.皮尔森(1904)的拟合优度检验或似然比检验(见假设检验),当h0成立,且一切 pi·>0和p·j>0时,统计量
为样本大小。根据K.皮尔森(1904)的拟合优度检验或似然比检验(见假设检验),当h0成立,且一切 pi·>0和p·j>0时,统计量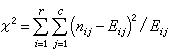 的渐近分布是自由度为 (r-1)(с-1) 的ⅹ2分布,式中Eij=ni·n·j/n 称为期望频数。当n足够大,且表中各格的Eij都不太小时,可以据此对h0作检验:若ⅹ2值足够大,就拒绝假设h0,即认为A与B有关联。在前面的色觉问题中,曾按此检验,判定出性别与色觉之间存在某种关联。
的渐近分布是自由度为 (r-1)(с-1) 的ⅹ2分布,式中Eij=ni·n·j/n 称为期望频数。当n足够大,且表中各格的Eij都不太小时,可以据此对h0作检验:若ⅹ2值足够大,就拒绝假设h0,即认为A与B有关联。在前面的色觉问题中,曾按此检验,判定出性别与色觉之间存在某种关联。若样本大小n不很大,则上述基于渐近分布的方法就不适用。对此,在四格表情形,R.A.费希尔(1935)提出了一种适用于所有 n的精确检验法。其思想是在固定各边缘和的条件下,根据超几何分布(见概率分布),可以计算观测频数出现任意一种特定排列的条件概率。把实际出现的观测频数排列,以及比它呈现更多关联迹象的所有可能排列的条件概率都算出来并相加,若所得结果小于给定的显著性水平,则判定所考虑的两个属性存在关联,从而拒绝h0。
在判定变量之间存在关联性后,可用多种定量指标来刻画其关联程度。例如,对一般的r×с表,可用列联系数表示之。
对一般的r×с表,特别是在多维表分析中,若无关联性(即独立性)的假设被拒绝,则通常还需要检验进一步的假设。例如对三维表,可能需要考虑一个变量是否与另外两个变量独立。对这类局部独立性的检验仍可用大样本的ⅹ2检验法。但是在多维情形,变量之间的关联性可能相当复杂。许多假设,直接用格概率表示是不方便的。一种处理方法是仿照线性统计模型,将格概率(或期望频数)的对数表示成各变量的主效应及各阶交互效应等未知参数的线性形式。这种模型称为对数线性模型,在此模型下,变量独立性的假设等价于交互效应等于零的假设。此外,还可以利用对数线性模型,根据实际观测频数,对各种具体模型进行拟合,并对各未知参数进行估计。估计的方法一般采用最大似然方法。由于这一类似然方程的解常无显式表示,通常需用迭代法求解,计算工作量很大。因此,多维列联表分析只在近代高速电子计算机的使用日益普及的情况下,才得到较为充分的发展,逐渐达到可以实际应用的程度。
参考书目
Y.M.M.Bishop,S.E.Fienberg and P.W.Holland,Discrete Multivariate Analysis, Theory and Practice,MIT Press, Cambridge, 1975.
M.Kendall and A. Stuart,The Advanced Theory of Statistics,4th ed., Vol. 2, Charles Griffin, London, 1979.