田间试验设计(卷名:农业)
design of field experiment
在试验田上设置与排列试验小区的方法。包括制订试验处理方案和试验小区设置方案,以及相应的资料搜集、整理和分析等,以便估计出无偏的、最小的试验误差,作为评价试验处理的依据。
发展简史
田间试验技术是在20世纪前后开始发展起来的。起初是采用大区形式、相邻排列和不设重复的方法。A.D.霍尔发现土壤差异是田间试验误差的主要来源。T.B.伍德和J.M.斯特拉顿于1910年最早在产量试验中设置对照区以纠正土壤变异,并提出估计试验误差的方法。1908年W.S.戈塞特首先提出“t”测验方法,即以t值测验平均数间差异的显著性,从而把处理平均效应的比较建立在统计学的基础上。1923年,英国著名统计学家R.A.费希尔首先运用随机排列概念创立“方差分析法”,用于分析田间和实验室的试验资料,并提出了随机区组和拉丁方的试验设计。此后,F.耶茨进一步阐明“因子试验的设计与分析”,D.J.芬尼(1945)发表了“因子试验的部分重复”等学术论著,于是出现不完全区组的混杂设计和部分重复设计。随着随机排列的引用使试验设计进入一个崭新的发展阶段,许多新的应用于不同范畴的试验设计也相继出现。中国于50年代以后引进了模型建立及其应用技术,内容主要包括回归设计分析、反应面分析等。
基本原则
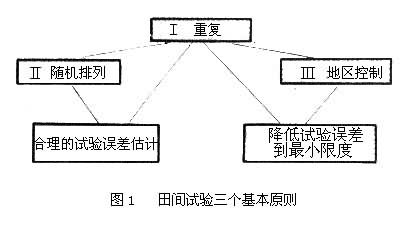
一个试验设计有若干个处理。如一个品种或一种栽培措施,就是一个处理。在田间试验中,安排处理的小块地段称试验小区。试验中同一处理种植的小区数目称重复。试验须设立对照区。近代田间试验以“误差控制”为理论基础,遵照以下3个基本原则进行设计:①重复原则。在试验田上每个处理只有设置几个重复,才能根据相同处理的各小区间的差异情况,估算其试验误差的大小。重复越多,处理平均值越可靠,因为平均数的标准差与重复次数的平方根成反比。②随机排列原则。其目的在于使各处理在重复内所占的小区位置机会均等,这样可以避免由土壤肥力、结构、田间管理等环境因素带来的系统性误差。随机排列只有在设置重复的基础上才能发挥作用。③局部控制原则。将试验田按照土壤肥力等因素划为几个局部地段,使地段之内环境条件比较一致,各个处理在每地段内只安排1个小区,成为1个区组(又称重复)。由于地段内土壤条件差异较小,各处理互相比较时可靠性较高。在上述3种情况下,与处理比较无关的变异的量可在统计分析中消除掉。田间试验设计3个基本原则的作用及其相互关系如图1所示。
小区排列方法
按试验小区排列方法可分为顺序排列与随机排列设计两大类:
顺序排列 每一重复内各处理都按照一定的次序排列。常用的方法有:①对比法。每隔2个处理小区设1个对照区,使各处理小区与相邻的对照区进行对比。可重复3~4次,此法因对照区用地太多,效率不高,已不常用。②间比法。每隔4个或9个处理设1对照区,重复2~4次,各重复可排成一或多排,各重复内的顺序可采用正向或逆向式(图2)。一般在育种试验的初、中期阶段(如鉴定圃)试验品系数目较多时采用此法。
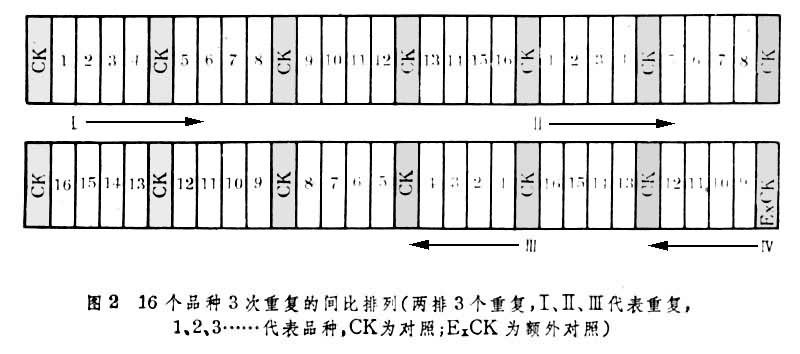
顺序排列设计简单,便于观察记载。并可用对照区检验土壤差异的影响。参试品种按品种熟期、株高等特征以及试验地地力差异的趋向排列,可减少边际效应和生产竞争的影响。但由于邻近小区的土壤肥力有相关性,在土壤差异显著时,处理间的比较将会发生系统误差,因而此类设计不能无偏地估计试验误差,不能应用统计分析进行显著性测验,对照区所占面积较大。
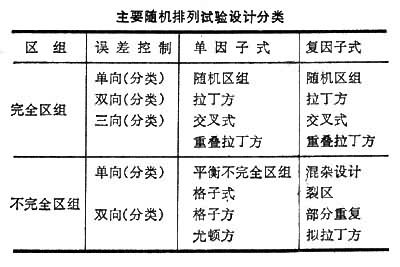
随机排列 根据“局部控制”的原则将试验处理的小区随机安排在各个区组内。这类设计根据处理因子的多少可分为单因子式与复因子式两类。根据误差控制方式,有一个方向、两个方向、三个方向之分。根据每一区组内是否包括全部处理数目又分为完全区组和不完全区组两类(见表)。
完全区组 每个重复的所有处理布置在一个区组内,区组数等于重复数。常用的布置形式有:
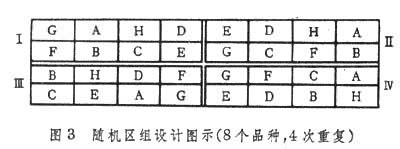
①随机区组。每个处理在每一区组内只能列入 1次,各处理在同一区组的排列完全随机,各区组内的随机排列是独立进行的。这种设计对试验地的土壤变异具有一个方向的控制效能(图3)。其优点是处理数目和重复数目没有严格限制,一般处理数目以20个以内为合适,重复次数以4~6次为宜。试验地的地形要求不严格,区组内的土壤肥力要均匀一致,要按田间试验的3个基本原则排列小区。试验的统计分析比较简单,即使有缺区也可分析。但当处理数目超过20时,由于一个区组所占土地面积较大,将会降低局部控制的效能。
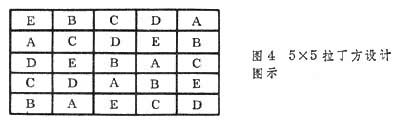
②拉丁方。将处理从两个方向排列成区组(或重复)如图4。每一直行及每一横行都是一个完全区组或重复,每个处理在每一直行或横行都只能出现一次,即重复数=处理数=直行数=横行数。拉丁方具有控制双向土壤差异的效能。设计步骤是先选择标准方,随后对直行、横行及处理进行随机排列,处理数目以5~8个为宜。
不完全区组 指一个区组不包括重复的全部处理,区组数多于重复数的设计。1935年由F.耶茨提出。后来获得发展并广泛应用于复杂的因子式试验。在因子式试验设计中,供试因子增加,处理组合数就很快地增多。例如,2因子试验每因子各具5个水平,则有25=32个处理组合。用随机区组或拉丁方设计在同一区组内已不具有土壤条件同质性,因而根据“局部控制”原则改用不完全区组设计以代替完全区组设计,使不完全区组之间的差异可从试验误差项内除去。其缺点是要牺牲某些处理比较的精确性,才能减少区组的容积,提高其他处理比较的精确度。常用的设计有以下 3种类型:
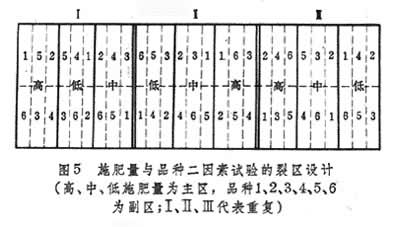
①裂区设计。将整个试验处理分为主处理与副处理。主处理布置在主区内,每一主区分裂为若干副区以布置副处理。主区可作随机区组或拉丁方排列,而副区一般作随机区组排列,也可作拉丁方排列(图5)。全试验对副处理而言,主区就是一个区组;若从全试验的整个处理组合看,主区仅是一个不完全区组。由于将主区分裂为副区,故称为裂区设计。在统计分析时有主、副区两个误差,副处理主效以及主处理×副处理互作效应的比较比主处理主效为精确。
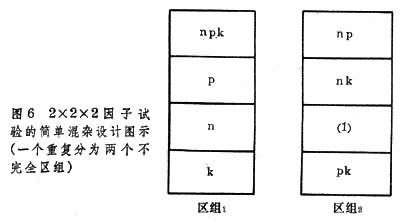
②混杂设计。把一个完全区组划分成几个较小的区组,各设置一部分处理,使区组效应和某试验因子的主效应或试验因子间的互作效应相混淆,是一种不完全区组的设计。各处理的重复次数少于区组数。在这类设计中,凡是已被“混杂”了的处理其主效应或互作效应无法和区组效应分开,不能被估算;但未被混杂的那些处理的主效应或互作效应仍然可以估算出来。如肥料三要素试验设计,全部处理组合有23=8个,即:对照(1)、n、p、np、k、nk、pk、npk,将它们分为两个区组;在区组内各包括4个处理组合(图6)。在估算处理效应时,NPK互作的效应和这2个区组的差异混杂在一起而被牺牲了,但在处理的主效应和处理间的低级互作效应的精确度则相应提高。这类设计又有完全混杂及部分混杂设计之分,适用于多因子试验。近代土壤肥料试验已普遍应用这种设计。
③平衡不完全区组。这类设计的原理,在于使各对处理出现在同一个不完全区组的次数相等,使各个处理间相互比较都能获得相同的精确度。如大豆毒素病试验以每片叶的两半片作为小区,在有6种处理进行试验的情况下,以A~F表示,则区组包括15对处理,即AB、AC、AD、AE、AF、BC、BD、BE、BF、CD、CE、CF、DE、DF、EF,全试验共有15个区组。此外,尚有格子式设计,适用于单因子或多品种比较试验。该设计采用“混杂”原理,将一个重复内的全部品种(或处理)分成若干组,各排成1个区组,使排列在不同区组的品种差异都和区组间差异“混杂”在一起。这种设计要求供试处理(品种)数必须是某个整数的平方,在编排时每个处理可看成是由两个水平数目相等的虚拟因子构成的各种水平组合中的 1个。设处理数为25,可由2个虚拟因子X和Y各有5个水平的5×5正方形来表示,其对应关系如下:
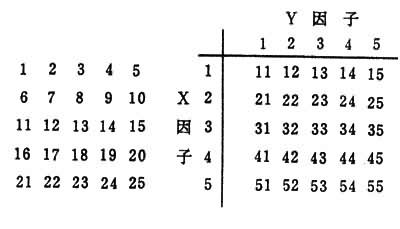 把对应于格子式同一行内的处理(即因子 X具同一水平的处理)设置为1个区组,计有5个区组,构成第Ⅰ群或称X群;再把对应于格子式同一列内的处理(即因子Y 具同一水平的处理)作为1个区组,也有5个区组,构成第Ⅱ群或称Y群。第Ⅰ群和第Ⅱ群各为1个重复,具体安排时,先将群内的区组随机排列,再将每一区组内的处理随机设置在小区上。这样区组的面积就小得多,可以收到良好的局部控制效果。这种简单的格子式设计,重复次数应为2的倍数,属于不平衡格子式设计。如果采用平衡格子式设计(25个品种),则须有6个群,重复为6次或其倍数。这类试验设计的统计分析比较复杂繁琐,但随着现代计算技术的迅速发展,已可在多品种的比较试验中普遍采用。
把对应于格子式同一行内的处理(即因子 X具同一水平的处理)设置为1个区组,计有5个区组,构成第Ⅰ群或称X群;再把对应于格子式同一列内的处理(即因子Y 具同一水平的处理)作为1个区组,也有5个区组,构成第Ⅱ群或称Y群。第Ⅰ群和第Ⅱ群各为1个重复,具体安排时,先将群内的区组随机排列,再将每一区组内的处理随机设置在小区上。这样区组的面积就小得多,可以收到良好的局部控制效果。这种简单的格子式设计,重复次数应为2的倍数,属于不平衡格子式设计。如果采用平衡格子式设计(25个品种),则须有6个群,重复为6次或其倍数。这类试验设计的统计分析比较复杂繁琐,但随着现代计算技术的迅速发展,已可在多品种的比较试验中普遍采用。发展趋势
近年来田间试验设计发展趋向表现在:①从单因子设计发展到复因子设计,目的在于明确几个因子的主效应和互作效应,使其更符合生产情况和实际需要,提高试验效率;②从完全区组设计发展为不完全区组设计,以减少处理组合数量,减少试验用材料和土地,并降低试验误差;③从单纯1年1点试验设计发展为多年多点综合性设计,旨在解决生产和科研上较为复杂的问题,同时提高试验精确度。
参考书目
马育华编著:《试验设计》,农业出版社,北京,1982。