植物群落分析(卷名:生物学)
analysis of plant community
一类生态学方法,即对植物群落(及其环境)的观测数据进行数学分析以求揭示其内在的生态学规律。植物群落,不同于生物群落,只包括一定地区内的植物,不包括动物和微生物,而在具体研究时更常集中于某些重点考察的生活型。但在植物群落分析中,特别是在排序研究中,环境因子也是主要研究内容,这所谓的环境因子也可以包括动物和微生物在内。植物群落分析方法,以从自然植物群落的统计学样本中测取得的群落属性与环境变化的定量数据为基础,应用数学原理和计算技术,对大量数据进行两种方法途径的综合:一种是把每个群落抽样单元,按其属性的相似性或相异性,聚合或划分为许多组群(分类单元),这称为群落的数值分类。另一种是把每个群落抽样实体视为点,在生境梯度或群落属性梯度的n维坐标空间中,序化地标记出来,这称为群落排序。数值分类和排序是定量地客观地对群落进行分类,揭示植物群落类型及其组成种群与环境相互关系的新技术。由于电子计算机的普遍应用,这些数值方法正在迅速发展,不断完善。
植物群落抽样 考察植物群落,选择出可代表该群落整体并具有一致性的一定区限,叫做群落样地。在样地内,为测计群落各项属性,如种类组成、生活型、种群数量特征、及环境因子特征可设置一定面积、形状或数量的小区(样方),这是常用的一种群落抽样方法。为了进行植物群落分析,要采取客观抽样法,即概率抽样。可以按具体情况在随机抽样、系统(规则)抽样、或分层抽样三者中择取一种。
样方抽样 样方面积与形状,原则上希望取最小表观面积,最适的形状。温带乔木群落最小面积一般为100~400平方米,热带森林更大些约1000~2000平方米;灌木群落约4~16平方米,草本群落1~4平方米,形状多采用正方,也可视具体需要和种的分布格局、微地貌不同,取圆形或长条。
样方数目多少,从统计学的要求,要有30~50个为好,如是分层抽样,则每个层区中要有6~10个。群落性态变异大时,数目要多些,反之可以减少。
无样方抽样 也叫威斯康星学派的点样法。是在群落样地内按随机或规则抽样,配置一定数目(通常是50~100个)样点。再以点为中心,按最近单株法、最近邻体法,随机对法、或中点四分法,记录每株乔木学名,测量株距(d)、胸径(图1),集合n次测定的株距d,计算出乔木的平均株距:
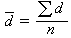 。由
。由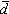 可算出每株乔木占有地表的平均面积:
可算出每株乔木占有地表的平均面积: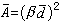 ,β是校正系数,上述4种无样方抽样方法的校正系数β,依次为 β=2,β=1.87,β=0.8,β=1。从乔木单株平均面积
,β是校正系数,上述4种无样方抽样方法的校正系数β,依次为 β=2,β=1.87,β=0.8,β=1。从乔木单株平均面积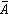 ,可计算单位样地面积的乔木密度:
,可计算单位样地面积的乔木密度: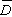 =1/(β
=1/(β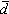 )2=1/
)2=1/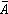 。同时,在每个样点上做灌木和草本记名小样方,根据乔木、灌木、草本种类的分布,可计算各个种的频度。
。同时,在每个样点上做灌木和草本记名小样方,根据乔木、灌木、草本种类的分布,可计算各个种的频度。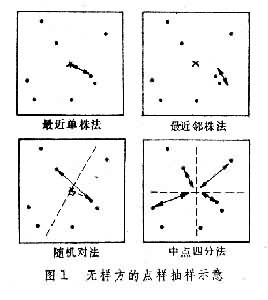
样方抽样和中心点抽样,分别适合于不同的对象、地区和目的。平坦地区的大面积森林适合用中心点取样,陡峭的山区森林适合用样方抽样。森林草地与荒漠植被则两种抽样都可适用。
原始数据的处理 抽样调查取得的各项群落属性的观测数据,由于属性的数据类型不同,量纲不一,数值大小悬殊,而各种分析方法对原始数据又各有一定要求,所以对原始数据要进行适当处理。首先要求类型统一,即把二元数据转化成数量数据,或者反之,因多数方法只适合于分析同一类型的数据。其次,要对原始数据的数值进行转换,即将原来数值x,转换成
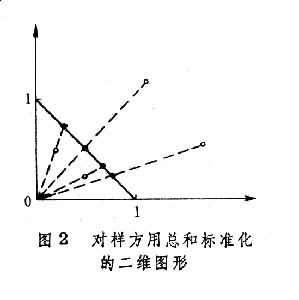
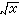 (只取正根),或其对数、倒数,或角度、概率等,以求更合理地体现它们的数量关系,使其具有一定的分布形式(如正态分布),或一定的数据结构(如线性结构)。第三,将原始数据标准化或中心化。原始数据的标准化,即用属性或实体的总和、或最大值、或极差、或模来除该属性的某个数据,实际上是把某个数值标准化为属性总和的比值,取值在0与1之间。例如群落分析中将种群绝对多度换算为相对多度。样方数据经标准化后,其几何意义是各样方点都从原来位置沿径向投影到单位弦上,成为线性序列(图2)。中心化主要是用平均值或离差来标准化各个原始数据。例如,平均值中心化是从属性或样方的各个原始数据中分别减去其平均值。中心化的几何意义在使坐标原点移到样方点的形心,由此给数值运算带来很大方便,第四,原始数据的缩减,指去掉一些代表性不好或数据不完整的样方,或者删去各样方中仅出现一次的孤种、或罕见种、或者生态学意义不大的常见种。缩减种数应当适当,不应影响研究结果。
(只取正根),或其对数、倒数,或角度、概率等,以求更合理地体现它们的数量关系,使其具有一定的分布形式(如正态分布),或一定的数据结构(如线性结构)。第三,将原始数据标准化或中心化。原始数据的标准化,即用属性或实体的总和、或最大值、或极差、或模来除该属性的某个数据,实际上是把某个数值标准化为属性总和的比值,取值在0与1之间。例如群落分析中将种群绝对多度换算为相对多度。样方数据经标准化后,其几何意义是各样方点都从原来位置沿径向投影到单位弦上,成为线性序列(图2)。中心化主要是用平均值或离差来标准化各个原始数据。例如,平均值中心化是从属性或样方的各个原始数据中分别减去其平均值。中心化的几何意义在使坐标原点移到样方点的形心,由此给数值运算带来很大方便,第四,原始数据的缩减,指去掉一些代表性不好或数据不完整的样方,或者删去各样方中仅出现一次的孤种、或罕见种、或者生态学意义不大的常见种。缩减种数应当适当,不应影响研究结果。原始数据综合表和数据矩阵 一般的群落调查,包括N个样方,P个种的数据,可列成N列,P行的数据表:
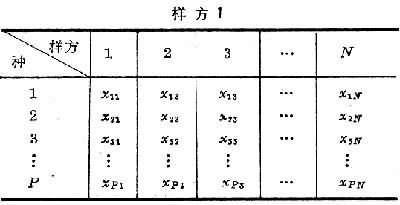
去掉表头,将表中数据用大括号括起来,就成了原始数据矩阵X,其中Xij(i=1,2,3,…,P;j=1,2,3,…,N)表示第j个样方、第i个种的原始数据。矩阵有P行,N列,第一行是同一物种。在N个样方中的数据,称为行向量。矩阵中每个数据,称为元素,其值可以是二元(定性)的,或数量(定量)的,但通常只取一种形式。
数值分类技术 是直接以样地内种的分布或种类组成的相对相似性数据为基础的群落分类方法。两个样地的相对相似性数值,叫做相似系数,相似与相异在数学上是互补的概念,两者都同样可表述两个样地相似的程度。
相似系数的计算方法虽很多,但基本上可归为2大类:一类是计算两个样地的群落种类组成成分的相似或相异程度,如匹配系数,关联系数等;另一类是计算两个样地中共有种的数量数据的相似或相异程度,如各种距离系数。
匹配系数与关联系数 依据数据矩阵中两个列(样地)的属性(种)的二元数据“存在”与“不存在”,可构成2×2列联表:

a是两个样地都存在的共有种的数目;d是都不存在的种数;b是样方1存在、样方2不存在的种数;c是样方2存在、样方1不存在的种数。据2×2列联表,可选以下任一公式,计算两个样地群落的相似性。
匹配系数的常用计算公式,有P.雅卡德(1901)的公式(1.1)和J.切卡诺夫斯基(1913)的公式(1.2),这两个公式取值均在[0,1]的区间内。当a=0时,取值为0,表示完全相异;当a=P(总的种数)时,取值为1,表示完全相似。1-相似系数=相异系数。
雅卡德匹配系数=a/(a+b+c) (1.1)
切卡诺夫斯基匹配系数=2a/(2a+b+c) (1.2)
关联系数 较常用的计算方法有尤尔(1912)的公式(2.1)和达格内利(1962)的公式(2.2),取值均在[-1,+1]的区间。最大的负关联;取值是-1,最大的正关联,取值为+1。
尤尔关联系数=(ad-bc)/(ad+bc) (2.1)
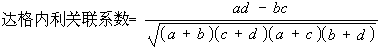 (2.2)
(2.2)距离系数 将两个样方表示为属性空间中的两个点时,则两样方的相异性即可用点间的距离来表示。设样方A和B中两个种是 x和y,则A和B在以 x和y为坐标轴的二维空间中,可表示为A点和B点(图3)。
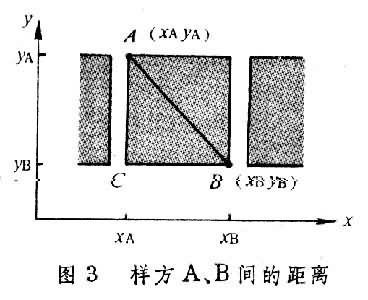
A点与B点之间的距离(d)的描述方式也很多,较常用的是布雷-柯蒂斯(3.1)距离公式,和欧氏距离公式(3.2和3.3)。公式中所用符号都是P×N 的数据矩阵X=(Xij),其中i=1,2,3,…,P个种,j=1,2,3,…,N个样方。
布雷-柯蒂斯距离公式:
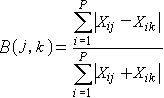 (3.1)
(3.1)欧氏距离公式:包括欧氏距离(d),及其平方(d2)
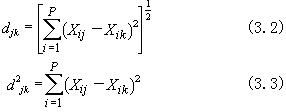
相似系数矩阵 把样方两个两个一组计算的相似系数数据列成 N×N 的相似矩阵,叫做样方间的相似系数矩阵
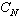 或
或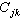 ;又叫Q矩阵。其中行和列的序号都表示样方,其中元素表示j 样方和k样方的相似系数(j,k=1,2,…,N)。
;又叫Q矩阵。其中行和列的序号都表示样方,其中元素表示j 样方和k样方的相似系数(j,k=1,2,…,N)。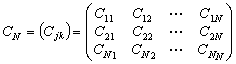
如果以种为单元,计算两个两个种之间的相似系数,列成P×P的相似系数矩阵,则叫做种间的相似矩阵CP,或
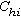 。这又叫R 矩阵,其中行和列的序号都表示种。元素表示第h种和第i种之间的相似系数(h,i=1,2,…,P)。
。这又叫R 矩阵,其中行和列的序号都表示种。元素表示第h种和第i种之间的相似系数(h,i=1,2,…,P)。植物群落的数值分类 群落分类的基本单位是样地(或样方),即群落实体。群落的内涵特征描述项目,如种类组成、种的频度、多度或显著度等的数值,即反映实体属性的信息。数值分类一般是按属性的相似或相异程度,将所有样地(或样方)集合分成若干个“同质的”样地(样方)组,使组内的成员尽可能地相似,不同组的成员尽可能地相异。即按群落所包含的各个属性、或规定的各项属性的变异幅度来分类。这些“同质”的样方组,可以是等级的分类类级(如传统分类的群丛,群属,群目,群系等),也可以是非等级的类级(统称为植物群落型)。通常按属性分类,用样方间的矩阵CN,称为正分析,或R分析方法。但也有用属性或种间矩阵CP的,称为逆分析,或 Q分析方法。分类的方法程序有二大类,即聚合分类,或分划分类。
等级聚合的分类 根据群落样地(样方)彼此间的相似程度,通过逐次合并,成为不同等级的“同质”样方组,或聚簇(Clustor)的分类方法,也叫聚簇分析。等级聚合程序最早被切卡诺夫斯基(1909)用于人类学资料的分类,以后才被波兰生态学家专门用于植被分类。
群落的聚簇分析,是多元的聚合方法。因为,群落样地或样方的N ×N 相似(异)系数矩阵CN是进行聚合的基础。无论哪一种相似(异)系数,其数值都是从所有属性的数据计算而来。聚合的程序一般是:①计算样地(样方)的 N×N 相似(异)系数矩阵CN;②先从CN中找出最相似的一对样地(方)合并为第一个聚簇;③重算(N-1)×(N-1)的相似(异)矩阵;④再从中找出与第一次合并聚簇最相似的另一个样地,并合并出另一个聚簇;⑤依次,重复逐次合并,直到全部样地合并为一。简言之,即从单个样方开始聚合,再是聚簇与单个样方、或与另外聚簇的聚合,自下而上直到把整个样方集合聚合为一体,结果是产生一个逐级聚合分析的枝谱图。
等级聚合过程中,有一个如何测算两个聚簇之间的距离的问题。需要一个适合的测度
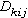 ,表示h聚簇到i和j联合聚簇之间距离。通常应用的七种聚合方法是:最近邻法;最远邻法;中线法;形心法;组平均法;平方和增量法;可变法等。兰斯和威廉斯(1967)为这些计算群簇距离的不同聚合方法,建立了一个统一的模型。
,表示h聚簇到i和j联合聚簇之间距离。通常应用的七种聚合方法是:最近邻法;最远邻法;中线法;形心法;组平均法;平方和增量法;可变法等。兰斯和威廉斯(1967)为这些计算群簇距离的不同聚合方法,建立了一个统一的模型。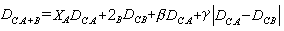 其中A,B,C,A+B均表示样方组 (群簇)。它们的样方数分别为nA,nB,nC,nA+B,A+B是A与B的并组,有n
其中A,B,C,A+B均表示样方组 (群簇)。它们的样方数分别为nA,nB,nC,nA+B,A+B是A与B的并组,有n =nA+nB。2A,2B,β,γ是常数(模型系数)。
=nA+nB。2A,2B,β,γ是常数(模型系数)。威廉斯和兰伯特(1966)提出的信息分析方法,用对称信息相似系数,即以样方组合并引起的信息增量 △I,作为A与B样方组间的相异性指标,将信息增量最小的成对群簇加以合并,其计算式为
△I(A,B)=I(A+B)-I(A)-IB
等级划分的分类 是从N 个样地(方)的集合开始,从上向下逐次分划。即先按相似性分为二个样方组,使组内相似性最大,组间相异性最大。接着对每个组再次分划,最终达到一定要求的“同质”样方组为止。
等级分划有单元和多元二类,现时通行的多为单元分划方法。如关联分析、组群分析和信息分析等方法。在群落数值分类中最常用的是关联分析方法。
关联分析,是基于在某个一致的群落中不同样方之间种类是不相关的,即二种间的关联是随机的,因而可把种间关系最小的一些样方,从样方集合中分划出来,作为一个类级。
关联分析的程序是:①依据二元(种的存在与不存在)原始数据矩阵X,求出P个种的种间关联系数矩阵CP=(Chi),(h,i=1,2,…,P);②从种的关联矩阵中找出一个与其他种关联最大的种A,称为临界种或关键种。③在样方集合中把含有临界种A的样方组(A),与不含临界种的样方(a)划分开成二个子样方组;④对(A)分别重复上面的程序,确定另一个临界种B,按B种的有或无,从A中划分出有B种存在的B样方组。如此反复进行,直到在分出的子组内部种间关联系数全都在规定的显著水平以下,即达到划分过程的“终止线”为止。⑤最后,也可得到等级划分分类的树谱图(图4)。
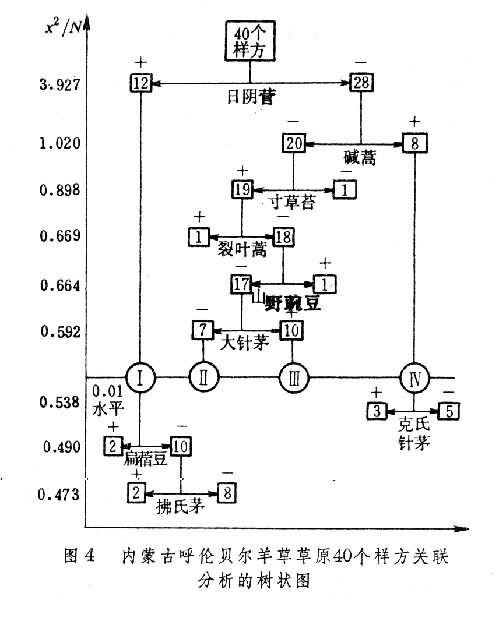 图中横坐标表示两条终止线的两个显著水平,纵坐标表示各次分划的X2/N的临界值和分划的过程。每一次分划的两支联结线下的植物种是该次分划的临界种,(+)号表示含有该临界种的样方组,样方数在方框内;(-)号表示无临界种的样方组,样方数记在方框内。
图中横坐标表示两条终止线的两个显著水平,纵坐标表示各次分划的X2/N的临界值和分划的过程。每一次分划的两支联结线下的植物种是该次分划的临界种,(+)号表示含有该临界种的样方组,样方数在方框内;(-)号表示无临界种的样方组,样方数记在方框内。现在,一般关联分析多采用威廉斯和兰伯特(1959,1960)的关联系数X2,或均方关联系数V2。
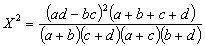
V2=X2/N式中a,b,c,d,N,都是二个种的2×2列联表中的数值。
选用这二种关联系数,是因为X2系数可供进行显著性检验,只有当 X2值大于或等于一定的显著水平,0.1,0.05,0.02或0.01(对应的临界值分别为2.706,3.841,5.412或6.635)时,才承认该两个种(种h和种i)在各该水平上是显著关联的。
组群分析,是以某些特定种的存在与不存在把样地(方)集合划分开来。选定特定种是依据它们与另外许多种共同出现的频度。
等级划分分类的多元分划方法,有依据样方组之间不相似性的组内平方距离的总和法;加权欧氏距离法,以及信息分析方法,不过,在等级划分中应用多元分析并不普遍。
植物群落的排序 是识别环境因子、种群和群落三个方面彼此之间相互联系的一类群落分析方法。排序的理论基础是在环境因子的梯度与植被的种群和群落属性的连续变化具有一定的秩序性。因而,可以将群落样地(样方)视为点,在以因子梯度为轴的坐标空间中分别把各个点的位置定出来,从而显示群落抽样及其属性(种群)的变化的抽象格局;明晰地反映群落类型物种分布,种群特征与主导环境因子的关系。
Л.Г.拉缅斯基(1924,1930),早在20世纪20年代就开始以环境因素如土壤肥力和土壤水分的梯度作为坐标轴,排列物种或群落的分布。之后,R.H.惠特克(1951,1967)的梯度分析则是从环境因子、种群、群落三方面的梯度来研究植物群落特征变化的规律。
梯度分析有二条途径。如果是在以已知的一个或多个环境梯度为轴的坐标空间中排列群落样地(样方抽样)的话,这叫做直接梯度分析。若是以从群落抽样(样方)的相似性或物种相关性的测定导出的抽象轴为坐标,排列出样地或种群的变化趋向,则叫做间接梯度分析。
直接梯度分析 是基于Л.Г.拉缅斯基(1924)对不同植物种的种群多度(密度)依从于环境条件的变化的统计学分析和表述。他认为群落生境通常随其不同环境因子的变化而呈现连续的变异。各个植物种在对环境的需求上具有多样性,因而,在生境的连续变化中会显示出不同物种各自的生态学的独特性。在以环境梯度为轴的空间里,直接表达种群、生态群组或群落分布模式的技术,就叫做直接梯度分析或排序。
直接梯度分析的程序是:①沿环境因子梯度间隔取样;②列出梯度群落表;③描绘环境梯度种群数量分布曲线;④划分生态组群,确定各生态组群的平均加权;⑤按以上步骤对另一环境因子进行分析,最后建立多维的复合梯度排列图解。
R.H.惠特克(1954,1960)建立了群落样地的比较定量法,用群落相似性百分率来表示各个群落样本(样地)的生态距离。PS=100-0.5∑|a-b|=∑min(a,b),a和b 是某个种在二个样方中的重要性值。还可直接用海拔高度和地貌单元二组复合梯度为x和y 轴,在图解上表述群落类型及种群分布格局与环境梯度的关系。
直接梯度分析技术,导致了种群独特性、种群连续统和植被复合连续统等新的群落学理论的产生。
间接梯度分析 也叫间接排序,是以自然群落样本(样方)的N×N 相似矩阵或相异矩阵,导出抽象轴,将样本作为点,在轴坐标空间里定位,从而揭示群落与环境关系的一类数学方法。包括连续统分析或组成梯度分析,极点排序,主分量分析,相互平均法,位置向量排序和典范分析等不同分析方法。它是80年代在植被分析中发展最快的领域。
极点排序 简写PO是广泛应用的一项简易有效的间接排序技术。操作程序是:
① 把N个群落样本中各个种的属性,标准化为重要值。
② 将成对样本按种的重要值计算两个样本的相似系数,或两者的相异系数。相似系数计算式为PS=∑min(x,y),式中的 min(x,y) 是共有物种在抽样x和y中的两个最小值。相异系数计算式为PD=1-PS。
③ 构造N×N 的相似系数和相异系数矩阵(是两个“半矩阵”)。
④ 建立第一排序轴(x 轴)。选取矩阵中相异系数值最大的两个样本, 设A与B两个样本作为x 轴的端点样本。令A位于x 轴的O端;则B为x 轴的远端,B与A的坐标距离,即A与B 的相异系数值。
⑤ 确定其他样本在x 轴上的坐标定位,及其与x轴的偏离值。设拟定位的样本为C,CA样对的PD值为DA,CB对的PD值为DB,A端与B端的距离为L,则C在x轴的坐标,是C与O 端A的距离x,x可根据比尔斯(1960)的公式计算:
x=
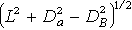 C与x 轴的偏离值h,计算式为
C与x 轴的偏离值h,计算式为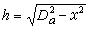 。
。⑥ 建立第二排序轴(y轴)。选取与x 轴偏离值最大的一个样本,设为D,D即可定为y轴的O端,再选取一个与D的相异系数最大的一个样本,设为E,E即是y轴的另一远端。其他样本,也可按照⑤的方法,确定它们在y 轴上的坐标。同样,还可选取第三排序轴(z轴)。极点排序通常只求二或三维排序坐标。
⑦ 排序效果检验。通常可按排序坐标求出各对样本间的欧氏距离d。再把N(N-1)/2个欧氏距离,与原来各对样本的相似系数作为二组数据,计算它们之间的相关系数r。如果r在0.9以上,即可认为排序后的样本距离与原数据所反映的相异性是相拟合的。排序效果是令人满意的。
极点排序如果用P×P 的属性相似矩阵,则可以显示种群与环境关系的秩序,还有人应用这一技术研究土壤特性的排序(蒙克,1965)。极点排序技术经过不断修正与改进,它在多领域里应用取得明显效果。具有计算简便,排序直观,生态学意义明晰等优点。
主分量分析 主分量分析 (PCA)是一种数据分析的数学方法,其目的是使多维空间中的样方点群投影到低维(2~3维)空间的坐标轴上,并力求获得原始数据的信息损失最小,或保存最多的线性序列。符合这种要求的坐标轴就称为主分量。古多尔(1954)将这种方法首先应用到群落分析。主分量分析排序的一般程序是:
① 对原始数据N×P 的X 矩阵中的属性(种的)数据中心化、标准化,使坐标原点称到处于N个点的形心(塣1,塣2,…,塣P)处。
② 计算属性(种)间的内积矩阵S。S=XXT=(
 ),(h,i=1,2,…,P)。
),(h,i=1,2,…,P)。③ 求出S的特征根和特征向量。S的特征根即特征多项式|S-γI|=0的P个根。将特征根依大小次序排列成h1≥h2≥…≥hP。再由us=Au的关系解出P个h相应的特征向量,并将它们依次按行排列,得到变换矩阵u。
④ 求N个样方的排序坐标。根据变换矩阵u,即可由Y=uX,计算出N个样方点对新坐标系的P个主分量的坐标。一般只需取各个样方点对第一、第二或第三主分量的值γ,以便在2~3维空间里画出N个样方点的直观排序图形。
⑤ 估计属性对主分量的作用。因为主分量是原有属性的线性组合,各个主分量本身所荷载的信息量只是原来各属性的综合效应,并非原来某一属性的作用。所以还要估计属性(种)在其所在主分量中所占的负荷量大小,由此可了解各属性对排序所起的作用大小。
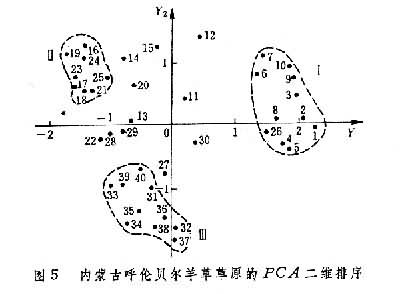
曾对内蒙古呼盟羊草草原的40个样方、32个种的数据,进行PCA分析排序,得到二维排序图(图5)。在这个PCA排序中,根据13个种计算第一和第二主分量保留的信息,只占总信息44.3%,加上第三主分量可增大到50.7%。其中第一维y1占28.4%,第二维y2占15.9%。排序的结果,将样方分布构成 3个点集,表征因生境的差异而存在三种群落类型。在y1轴的左面和右面是与土壤水分梯度有关的A与B两个群落;在y2的上面和下面的B和C两个群落是与土壤盐渍化梯度有关的两个群落。对y1作用最大的种为不太耐旱的日阴菅(负荷量2.6);对y2作用大的是只存在于半干旱生境的柴胡 (1.9)和只分布在盐渍化土壤中的碱蒿(-1.81)。这3个种也就是划分羊草草原 3个群丛组的临界种。
相互平均分析法 也称对应分析,是同时进行样地或物种(实体和属性)的交互排序技术。即对同一套原始数据,同时交互使用正分析(R分析)和逆分析 (Q分析),所以也叫相互排序方法。它也是一种用迭代法求特征向量的算法,但由于同时可得到对属性的排序,比PCA法仅只是能获得属性负荷更为切合实用,更接近于梯度分析或极点排序,也更便于作出合理的生态学解释。相互平均法的一般程序是:
① 计算物种与抽样的排序坐标间的相互平均关系。
② 用迭代法求出第一轴上的y和z。
③ 求其他轴上的排序坐标。
④ 估计特征值(即相应轴的方差)γ。
⑤ 对物种和样本(样方)进行排序。
排序方法的发展,正面临一个如何真实反映生境、物种、群落三者间的非线性关系,及其连续、随机和不确定性等特征的问题。
数值分类,早期或现代发展的排序,都仅仅是研究植物群落生态学的一种数学技术,它只是手段而不是目的。重要的是如何应用生态学实际知识和理论思维,指导方法的应用并对方法的结果作出正确的判断和解释。
参考书目
阳含熙、卢泽愚:《植物生态学的数量分类方法》,科学出版社,北京,1981。
周纪纶:植被的多因子生态系统分析途径,《植物生态学与地植物学丛刊》,1981。
R.H.惠特克主编,周纪纶等译:《植物群落分类》,科学出版社,北京,1985。
R.H.惠特克主编,王伯荪译:《植物群落排序》,科学出版社,1986。