计算复杂性(卷名:数学)
computational complexity
现代理论计算机科学中最重要的分支之一,它研究各种问题类在计算时所需要耗费的时间、空间等资源的多少,是可计算性理论的新发展。
从可计算性到计算复杂性 什么样的问题类是可计算的?这是数学、数理逻辑学和早期计算机科学所关心的一个重要问题。为了回答这个问题,可以给出一个计算的模型,然后规定,凡是这个模型能计算的问题类就叫作可计算的,否则就叫作不可计算的。于是产生了各种计算的模型:图灵机、递归函数、λ 演算、马尔可夫算法和递归算法等。但是,会不会有一类问题,在一个模型中是可计算的,而在另一个模型中却是不可计算的呢?如果这样,一个问题类的可计算性就依赖于模型,而不是问题类本身的性质了。著名的丘奇-图灵论题回答了这个问题。这个论题说:“凡是合理的计算模型都是等价的,即一个模型能算的问题类别的模型也能算,一个模型不能算的别的模型也不能算。”这个论题不是一个严格的命题,无法给于一般的证明,但可以对一个个具体的模型去验证它的正确性。但是,对于一个问题类,只知道它能否计算还很不够,更有实际意义的是要知道计算起来要耗费多少时间,要用多大的空间来存储计算的中间结果等等。为了回答这些进一步的问题,就产生了计算复杂性理论。
资源计算时间、存储大小都称为资源。严格地讲,每一种资源的定义都依赖于特定的计算模型。对各种计算模型,资源的定义虽不一样,但主要的可分为三类:
① 串行时间(简称时间) 它是计算过程中的总运算量,即把计算分成一些原始的步骤,完成这些步骤所需要的总时间。
② 空间 它是为了保存中间结果所需要的存储器的大小。例如在计算时用一块黑板来打草稿,每一单位面积假定可以写一个符号,不用了还可以擦掉。在计算时所需黑板面积就是空间。
③ 并行时间 它是并行计算所需要的时间,亦即如果多人或多处理机协同计算,解决一个问题所需要的时间。
问题的大小和复杂性的度量 和可计算性一样,复杂性总是对于一个特定的问题类来讨论的,它包括无穷多个个别问题,有大有小。例如,对矩阵乘法这样一个问题类,相对地说,100阶矩阵相乘是个大问题,而二阶矩阵相乘就是个小问题。可以把矩阵的阶 n作为衡量问题大小的尺度。又如在图论问题中,可以把图的顶点数n作为衡量问题大小的尺度。一个个别问题在计算之前,总要用某种方式加以编码,并可把这个编码的长度 n作为衡量问题大小的尺度。
当给定一个算法以后,计算大小为n的问题所需要的时间、空间等就可以表示为 n的函数。这个函数就可作为该算法的时间或空间复杂性的度量。严格地讲,是这个特定的问题类在某一特定计算模型中某一特定算法的复杂性之度量。当要解决的问题越来越大时,时间、空间等资源耗费将以什么样的速率增长,即当n趋向于无穷大时,这个函数的性状如何,增长的阶是什么,这就是计算复杂性理论所要研究的主要问题。
上界和下界 在计算同一个问题类时,算法有好坏之别。例如,要确定一个具有n个顶点的无向图中有没有回路,以前最好的算法所需工作空间为 S(n)=O(log2n)(S(n)=O(ƒ(n))的意思是当n充分大时,S(n)不超过ƒ(n)的一个正的常数倍)。但是最新的算法只需要O(logn)的工作空间就够了。这说明,O(log2n)只是原来那个算法的复杂性,而并非这个回路问题的内在复杂性。或者说O(log2n)是回路问题空间复杂性的一个上界,而O(logn)则是一个更好的上界。对于回路问题来说,还可以证明,任何算法都至少需要正比于logn的工作空间。也即对于任何算法, 空间复杂性S(n)=Ω(logn)(S(n)=Ω(ƒ(n))的意思是当n充分大时S(n)不小于ƒ(n)的一个正的常数倍)。 因此可以认为Ω(logn)是回路问题空间复杂性的一个下界。一个问题类的内在复杂性介于最小的上界和最大的下界之间。在这个例子中两者重合了,因此可以说回路问题的空间复杂性正比于logn,记为S(n)=嘷(logn)。
又如,两个n位二进整数的乘法在一个适当的模型之下,总运算量(时间)为O(n2),对算法略加改进可以达到O(n1.5),现在最好算法的时间只需O(n·logn·loglogn)。如果进一步采用存储修改机器做模型,则时间可以进一步缩短到O(n)。可见一个问题的复杂性是依赖于所选择的模型的。
相似性原理 如上所述,一个问题类的时间、空间等资源的复杂性是依赖于模型的:在有的模型中较高,在另一些模型中则较低。现在较为重要而有特色的计算模型有:多带图灵机器、多变址随机存取机器、存储修改机器、齐一线路、向量机器、硬件修改机器等等。这样一来,复杂性的问题仍然没有一个统一的客观依据。相似性原理解答了这个问题。按此原理,一个问题类内在的并行时间、空间和串行时间的复杂性在所有理想的计算模型中都没有本质的差异。用数学的说法,各种模型可以互相模拟,而且模拟者需用的并行时间、空间和串行时间都分别不超过被模拟者所需的并行时间、空间和串行时间的一个多项式,三者同时成立。所以在只差一个多项式的范围内,复杂性的确是一个不依赖于模型的客观实在。这是丘奇-图灵论题在复杂性理论中的新发展。对于上面提到的计算模型,相似性原理已被证明是正确的。
巡回和周相 在上面提到的模型中,有的是串行模型,有的则是并行模型。如前所述,并行模型的串行时间相当于计算过程中的总运算量。至于串行模型的并行时间,可以认为它是一个叫作巡回的量。简而言之,巡回是计算过程中周相的总数。而周相则是计算过程中的一个阶段,在此阶段内写入工作空间的信息不会在同一阶段中读出。由此可见,串行模型的巡回相应于并行模型的并行时间。对于一个问题类而言,存在一个高速并行算法的充要条件是可以找到一个具有小的巡回数的串行算法。
对偶性原理 并行时间和空间之间还呈现出某种对称的性质,这就是对偶性原理。例如可以证明,对于一个问题类而言,存在一个节省并行时间的算法的充要条件是存在一个节省工作空间的算法。因此在这个意义下并行时间和空间是可以互相转换的。
平均复杂性和最坏情况复杂性 对于大小都为 n的不同问题,一个算法所需用的时间、空间等资源也可能不相同。那么如何定义它的复杂性?一种方法是考虑最不利的情况,例如,把大小为n的各问题中花费的最长时间作为时间的复杂性。另一种方法是对所有可能情况按某种分布取平均值,这就是平均复杂性。显然,它不高于最坏情况复杂性。由于平均复杂性依赖于问题的分布,难于作数学的处理,所以常用的是最坏情况复杂性。
代数复杂性 相似性原理所涉及的模型主要研究计算中按位运算的总量时间,按位计的中间结果存储量空间和计算的深度(并行时间)等等,所以可称为按位的复杂性。代数的复杂性理论则研究在一个代数系统中(例如实数域中)从给定变量出发去计算某些函数所需要的代数运算(例如加法、乘法)代数判断(例如大于或等于)的次数(时间),所需中间变元的个数(空间),计算的深度(并行时间)等等。在实际运算中,既不能给出一个无限长的实数,也不能在一个单位时间内完成两个实数的乘法。真正的算术运算都是通过近似小数的按位运算得出来的。所以按位的复杂性具有更为基本的意义。通过下面的例子,可以得到关于代数复杂性的一些感性认识。通常两个n阶矩阵相乘要做n3次数乘法,V.斯特拉森找到了一个算法,只需做
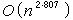 次数乘法。此后这个上界又被许多人不断改进到
次数乘法。此后这个上界又被许多人不断改进到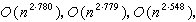
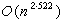 ,至1981年12月,又改进为
,至1981年12月,又改进为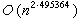 。D.科普尔史密斯和S.维诺格拉特还证明:最好的算法不存在,也就是说这个上界可以永远改进下去。
。D.科普尔史密斯和S.维诺格拉特还证明:最好的算法不存在,也就是说这个上界可以永远改进下去。参考书目
A.V.Aho,J.E.Hopcroft and J.D.Ullman,The Design and Analysis of Computer Algorithms,Addison-Wesley, Reading Mass., 1974.
洪加威著:《计算──理论和现实的可计算性》,科学出版社,北京,1984。
J.E.Hopcroft and J.D.Ullman,Introduction to AutoMata Theory, languages and Computation,Addison-Wesley,Reading Mass., 1979.