区间估计(卷名:数学)
interval estimation
参数估计的一种形式。通过从总体中抽取的样本,根据一定的正确度与精确度的要求,构造出适当的区间,以作为总体的分布参数(或参数的函数)的真值所在范围的估计。例如,估计一种药品所含杂质的比率在1~2%之间;估计一种合金的断裂强度在1000~1200千克之间,等等。在有的问题中,只需要对未知量取值的上限或下限作出估计。如前例中,一般只对上限感兴趣,而在第二例中,则只对下限感兴趣。
在数理统计学中,待估计的未知量是总体分布的参数θ或θ的某个函数g(θ)。区间估计问题可一般地表述为:要求构造一个仅依赖于样本X=(x1,x2,…,xn)的适当的区间[A(X),B(X)],一旦得到了样本X的观测值尣,就把区间[A(尣),B(尣)]作为θ或g(θ)的估计。至于怎样的区间才算是“适当”,如何去构造它,则与所依据的原理和准则有关。这些原理、准则及构造区间估计的方法,便是区间估计理论的研究对象。作为参数估计的形式,区间估计与点估计是并列而又互相补充的,它与假设检验也有密切的联系。
置信区间理论 这是1934年,由统计学家J.奈曼所创立的一种严格的区间估计理论。置信系数是这个理论中最为基本的概念。
置信系数 奈曼以概率的频率解释为出发点,认为被估计的θ是一未知但确定的量,而样本X是随机的。区间[A(X),B(X)]是否真包含待估计的θ,取决于所抽得的样本X。因此,区间 [A(X),B(X)]只能以一定的概率
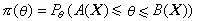 包含未知的θ。对于不同的θ,π(θ)之值可以不同,π(θ)对不同的θ取的最小值1-α(0<α<1)称为区间[A(X),B(X)]的置信系数。与此相应,区间[A(X),B(X)]称为θ的一个置信区间。这个名词在直观上可以理解为:对于“区间[A(X),B(X)]包含θ”这个推断,可以给予一定程度的相信,其程度则由置信系数表示。
包含未知的θ。对于不同的θ,π(θ)之值可以不同,π(θ)对不同的θ取的最小值1-α(0<α<1)称为区间[A(X),B(X)]的置信系数。与此相应,区间[A(X),B(X)]称为θ的一个置信区间。这个名词在直观上可以理解为:对于“区间[A(X),B(X)]包含θ”这个推断,可以给予一定程度的相信,其程度则由置信系数表示。对θ的上、下限估计有类似的概念,以下限为例,称A(X)为θ的一个置信下限,若一旦有了样本X,就认为θ不小于A(X),或者说,把θ估计在无穷区间[A(X),∞)内。"θ不小于A(X)"这论断正确的概率为

 θ)。π1(θ)对不同的θ取的最小值1-α(0<α<1)称为置信下限A(X)的置信系数。
θ)。π1(θ)对不同的θ取的最小值1-α(0<α<1)称为置信下限A(X)的置信系数。在数理统计中,常称不超过置信系数的任何非负数为置信水平。
优良性准则 置信系数1-α 反映了置信区间[A(X),B(X)]的可靠程度,1-α愈大,[A(X),B(X)]用以估计θ时,犯错误(即θ并不在[A(X),B(X)]之内)的可能性愈小。但这只是问题的一个方面。为了使置信区间[A(X),B(X)] 在实际问题中有用,它除了足够可靠外,还应当足够精确。比如说,估计某个人的年龄在 5至95岁之间,虽十分可靠,但太不精确,因而无用。通常指定一个很小的正数α(一般,α 取0.10,0.05,0.01等值),要求置信区间[A(X),B(X)]的置信系数不小于1-α,在这个前提下使它尽可能地精确。对于“精确”的不同的解释,可以导致种种优良性标准。比较重要的有两个:一是考虑区间的长度B(X)-A(X)愈小愈好。这个值与X有关,一般用其数学期望Eθ(B(X)-A(X))作为衡量置信区间[A(X),B(X)] 精确程度的指标。这个指标愈小, 置信区间的精确程度就愈大。另一个是考虑置信区间 [A(X), B(X)]包含假值(指任何不等于被估计的 θ 的值)θ′ 的概率
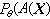
 ,它愈小,[A(X),B(X)]作为θ的估计的精度就愈高。
,它愈小,[A(X),B(X)]作为θ的估计的精度就愈高。如果A(X)是θ的置信下限,则在保证A(X)的置信系数不小于1-α的前提下,A(X)愈大,精确程度愈高。这也可以用[A(X) ,∞)包含假值θ′(θ′<θ)的概率
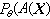
 来衡量,此概率愈小,置信下限A(X)的精确程度愈高。对置信上限有类似的结果,若在某个准则下,一个置信区间(或上、下限)比其他置信区间都好,则称它为在这个准则下是一致最优的。例如,在上述准则下,置信系数1-α的一致最优置信下限A(X)定义为:A(X)有置信系数1-α ,且对任何有置信系数1-α的置信下限A1(X),当θ′<θ时,成立
来衡量,此概率愈小,置信下限A(X)的精确程度愈高。对置信上限有类似的结果,若在某个准则下,一个置信区间(或上、下限)比其他置信区间都好,则称它为在这个准则下是一致最优的。例如,在上述准则下,置信系数1-α的一致最优置信下限A(X)定义为:A(X)有置信系数1-α ,且对任何有置信系数1-α的置信下限A1(X),当θ′<θ时,成立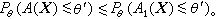
有时,对所考虑的置信区间(或上、下限)加上某种一般性限制,在这个前提下寻找最优者。无偏性是经常用的限制之一,如果一个置信区间(上、下限)包含真值θ的概率,总不小于包含任何假值θ′的概率,则称该置信区间(上、下限)是无偏的。同变性(见统计决策理论)也是一个常用的限制。
求置信区间的方法 最常用的求置信区间及置信上、下限的方法有以下几种。
一种是利用已知的抽样分布(见统计量)。例如,设x1,x2,…,xn为正态总体N(μ,σ2)(见正态分布)中抽出的样本,要作μ 的区间估计,记
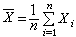 ,
, ·
· 则
则 服从自由度为n-1的t分布。指定α>0,找这个分布的上α/2分位数tα/2(n-1),则有
服从自由度为n-1的t分布。指定α>0,找这个分布的上α/2分位数tα/2(n-1),则有 即
即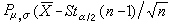
 由此得到 μ 的一个置信系数为 1-α 的置信区间
由此得到 μ 的一个置信系数为 1-α 的置信区间 
 。类似地可以定出μ的置信系数为1-α的置信上、下限分别为
。类似地可以定出μ的置信系数为1-α的置信上、下限分别为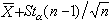
 。
。另一种是利用区间估计与假设检验的联系,设要作θ的置信系数为1-α 的区间估计,对于任意的θ0,考虑原假设为 H:θ=θ0,备择假设为 K:θ≠θ0。设有一水平为α 的检验,它当样本X属于集合A( θ0)时接受H。若集合{θ0∶X∈A(θ0)}是一个区间,则它就是θ的一个置信区间,其置信系数为1-α。就上例而言,对假设H:μ=μ0的检验常用t检验:当
 时接受μ=μ0,集合
时接受μ=μ0,集合  即为区间
即为区间 这正是前面定出的μ的置信区间。若要求θ的置信下限(或上限),则取原假设为θ≤θ0(或θ≥θ0),备择假设为θ>θ0(或θ<θ0),按照同样的方法可得到所要求的置信下(上)限。
这正是前面定出的μ的置信区间。若要求θ的置信下限(或上限),则取原假设为θ≤θ0(或θ≥θ0),备择假设为θ>θ0(或θ<θ0),按照同样的方法可得到所要求的置信下(上)限。还有一种方法是利用大样本理论(见大样本统计)。例如,设x1,x2,…,xn为抽自参数为p的二点分布(见概率分布)的样本,当n→∞时,
 依分布收敛(见概率论中的收敛)于标准正态分布N(0,1),以 uα/2记N (0,1)的上 α/2 分位数,则有
依分布收敛(见概率论中的收敛)于标准正态分布N(0,1),以 uα/2记N (0,1)的上 α/2 分位数,则有
 。所以,
。所以, 可作为p的一个区间估计,上面的极限值1-α就定义为它的渐近置信系数。
可作为p的一个区间估计,上面的极限值1-α就定义为它的渐近置信系数。费希尔的信任推断法 20世纪30年代初期,统计学家R.A.费希尔提出了一种构造区间估计的方法,他称之为信任推断法。其基本观点是:设要作θ的区间估计,在抽样得到样本X以前,对θ一无所知,样本X透露了θ的一些信息,据此可以对θ取各种值给予各种不同的“信任程度”,而这可用于对θ作区间估计。例如,设X是从正态总体N(θ,1)中抽出的样本,则
 服从标准正态分布N(0,1),由此可知,对任何α<b)有
服从标准正态分布N(0,1),由此可知,对任何α<b)有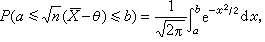 即
即 费希尔把这个等式解释为:在抽样以前,对于θ落在区间
费希尔把这个等式解释为:在抽样以前,对于θ落在区间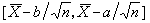 内的可能性本来一无所知,通过抽样,获得了上述数值,它表达了统计工作者对这个区间的"信任程度",若取b)=-α=uα/2,则得到区间
内的可能性本来一无所知,通过抽样,获得了上述数值,它表达了统计工作者对这个区间的"信任程度",若取b)=-α=uα/2,则得到区间
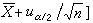 ,其信任程度为 1-α。即当用上述区间作为θ的区间估计时,对于“它能包含被估计的θ”这一点可给予信任的程度为1-α。
,其信任程度为 1-α。即当用上述区间作为θ的区间估计时,对于“它能包含被估计的θ”这一点可给予信任的程度为1-α。在本例以及其他某些简单问题中,用费希尔的方法与用奈曼的方法得出一致的结果。但是,这两个方法不仅在基本观点上不一致,而且在较复杂的问题中,所得出的结果也不同。一个著名的例子是所谓的费希尔-贝伦斯问题:设两个正态分布
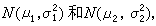 μ1,μ2,σ娝,σ娤都未知,要求μ1-μ2的区间估计。费希尔用他的方法提供了一个与奈曼理论不一致的解法,奈曼在1941年曾对此进行了详尽的讨论。
μ1,μ2,σ娝,σ娤都未知,要求μ1-μ2的区间估计。费希尔用他的方法提供了一个与奈曼理论不一致的解法,奈曼在1941年曾对此进行了详尽的讨论。另外,贝叶斯方法(见贝叶斯统计)也是一个重要的构造区间估计的方法。统计决策理论中引进的一些概念和优良性准则,也可用于区间估计。此外序贯方法(见序贯分析)在区间估计中也有了相当的发展。
区域估计 有时要对两个或更多的参数θ=(θ1,θ2,…,θk)(k>1),例如正态分布N(μ,σ2)中的μ与σ2,同时进行估计;这时,每当有样本X,就由X在θ的取值的k维空间Rk内定出一个区域Q(X),而把θ估计在Q(X)内。这种估计叫做区域估计。所用区域一般为比较简单的几何形状,如长方体、球或椭球等。关于区域估计的置信系数、优良性准则及其求法等,与区间估计情况相似。
容忍限与容忍区间 这是一个与区间估计有密切联系的概念,但处理的问题不同。给定β,у,0<β<1,0<у<1,以F记总体分布。若T(X)为一统计量,满足条件


 ,则称 T(X)为总体分布F 的上(β,у)容忍限。类似地可定义下(β,у)容忍限。若T1(X)和T2(X)为两个统计量,T1(X)≤T2(X),且
,则称 T(X)为总体分布F 的上(β,у)容忍限。类似地可定义下(β,у)容忍限。若T1(X)和T2(X)为两个统计量,T1(X)≤T2(X),且
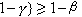 ,则称 [T1(X),T2(X)] 为总体分布的一个(β,у)容忍区间。例如,X是某产品的质量指标,而F为其分布,则(β,у)容忍区间[T1(X),T2(X)]的意义是:至少有1-β的把握断言“至少有100(1-у)%的产品,其质量指标落在区间[T1(X),T2(X)]之内”。可以说,容忍区间估计的是总体分布的概率集中在何处,而非总体分布参数。
,则称 [T1(X),T2(X)] 为总体分布的一个(β,у)容忍区间。例如,X是某产品的质量指标,而F为其分布,则(β,у)容忍区间[T1(X),T2(X)]的意义是:至少有1-β的把握断言“至少有100(1-у)%的产品,其质量指标落在区间[T1(X),T2(X)]之内”。可以说,容忍区间估计的是总体分布的概率集中在何处,而非总体分布参数。参考书目
J.Neyman, Outline of a Theory of Statistical Estimation Based on the Classical Theory of Probability,Philosophical Transactions of the Royɑl Society, Vol. 236, 1937.
陈希孺著,《数理统计引论》,科学出版社,北京,1981。